Data powers almost every part of a business—from managing customer information to supporting daily operations. When a company loses its data, the consequences can be severe. To minimize these risks, organizations rely on something called a DRP. So, what exactly does that mean?
DRP stands for Disaster Recovery Plan, a strategic plan that helps organizations restore data and continue operations after unexpected disruptions.
👀 DRP at a Glance
- Goal: Restore critical IT functions and data quickly and predictably.
- Scope: Systems, applications, infrastructure, files, databases, SaaS exports.
- Outputs: Runbooks, communication plans, recovery checklists, and test reports.
In this article, we'll break down the full DRP meaning, its key components, why it matters for your business, and how modern solutions like AnySecura make disaster recovery effortless through automation and intelligent backups.
Why DRP Matters For Businesses
Every minute of system failure or data loss costs more than money, it costs trust, reputation, and customer confidence. A Disaster Recovery Plan (DRP) gives business leaders the one thing they need most in a crisis: control.
1. Cut revenue loss, keep operations running
When your systems stop, so does your business. Orders can't be processed, emails can't be sent, and employees can't work properly. Even a few hours of downtime can lead to big financial losses and unhappy customers. A strong DRP makes sure your most important systems, like payment tools, databases, and communication channels, can recover quickly. That means your business keeps running, your team stays productive, and you don't lose the trust of your clients. It's not just about fixing computers, it's about keeping your whole company moving.
2. Pay fewer fines, lower legal risk
Data isn't just valuable, it's also something you're responsible for. When important files are lost or stolen, it can lead to fines, legal issues, and long hours trying to fix everything. Many industries, such as healthcare and finance, have strict rules that require companies to protect and recover their data properly. A good DRP helps you follow those rules and avoid costly penalties. It also helps you plan ahead, so your team knows exactly what to do instead of panicking when problems appear.

3. Keep more customers, protect your brand
Customers remember how a company reacts when trouble hits. If your systems stay down for too long, they might lose confidence and move to competitors. But if you recover fast and communicate clearly, it shows that your company is reliable and professional. A tested DRP makes that possible, it helps you respond calmly, update your customers quickly, and show that you're in control. Over time, that kind of reliability builds real trust and strengthens your brand image.
4. Decide faster when it matters most
During a crisis, every minute counts. Without a plan, people waste time figuring out who should do what or which system to fix first. A DRP removes that confusion. It gives clear instructions, assigns roles to each person, and sets priorities so leaders can make fast and confident decisions. This kind of structure not only saves time but also reduces stress. When everyone knows their part, recovery happens faster, and the company can return to normal with less damage and panic.
What Is Considered A Disaster?
In business, a disaster means any event that suddenly stops your operations or damages your data and systems. It doesn't have to be dramatic, even a short outage or one wrong click can cause serious loss.

1. Cyberattacks and Ransomware
This is one of the most common modern "disasters." About 73% of companies believe they are at risk of a major cyberattack, and 41% of small businesses have already experienced one. [source] When ransomware hits, the real cost goes far beyond paying the ransom, it includes system recovery, legal investigations, customer trust loss, and downtime. These hidden costs often make recovery much harder than expected.
2. Hardware or System Failures
Not every disaster comes from hackers. Sometimes, it's simply a failed server, a broken hard drive, or a faulty software update. Studies show that for large enterprises, one hour of downtime can cost over $1 million.[source] Even for small or mid-sized businesses, downtime can still cost hundreds or thousands of dollars per minute.[source]
3. Human Errors
People make mistakes, deleting important files, misconfiguring systems, or forgetting backups. One small mistake can easily snowball into hours of disruption or even permanent data loss if there's no recovery plan in place.

What Is a malicious insider? Learn how to identify different types, spot warning signs, and use effective strategies to protect your organization’s data and systems. Learn more>>
4. Natural Disasters and Power Outages
Earthquakes, floods, hurricanes, or large-scale power outages can directly damage equipment or stop operations for days. What's worse, research shows that natural disasters often come with secondary risks, such as cyberattacks exploiting the chaos.[source]
5. Supplier or Network Outages
Sometimes the problem doesn't come from inside your company. A cloud service outage, an internet failure, or a third-party provider's issue can also interrupt your business. If one link in your operational chain breaks, your entire workflow might be forced to stop.
🎯 Reality Check
In short, a "disaster" is any event that stops your business from running normally, no matter how big or small. The real question isn't if it will happen, but when. That's why being prepared with a Disaster Recovery Plan isn't just a smart move, it's essential.
How Businesses Recover After A Disaster?
Key Metrics for Effective Recovery
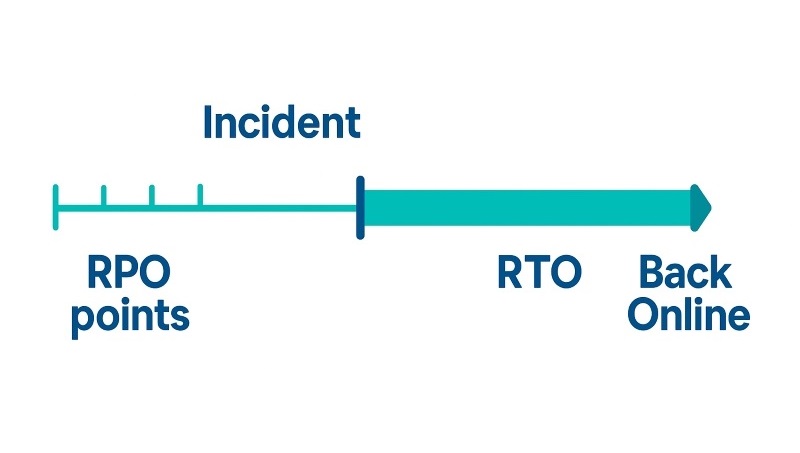
RTO: How Fast You're Back
RTO, short for Recovery Time Objective, defines how long your business can afford to be offline after an incident. Setting a realistic RTO helps determine the type of recovery methods and resources needed. Shorter RTOs usually require more investment in automation and failover systems, but they significantly reduce operational disruption.
Example
"RTO 4 hours" = the system must be restored and usable within 4 hours at the latest.
For a public website, you might aim for an RTO of 30 minutes so that customers can quickly regain access after downtime.
RPO: How Much You Can Lose
RPO, short for Recovery Point Objective, represents the maximum acceptable data loss your business can tolerate. Companies with strict RPOs, such as financial institutions, often use continuous replication to remote data centers so that, even in a disaster, only a few minutes of data are lost.
Example
"RPO 1 hour" = you can lose up to the last 1 hour of changes.
A design firm may set an RPO of 1 hour. In contrast, a stock-trading platform might target an RPO of 5 minutes or less, using real-time data replication to make sure transactions are never lost.
8 Common Ways to Recover After A Disaster
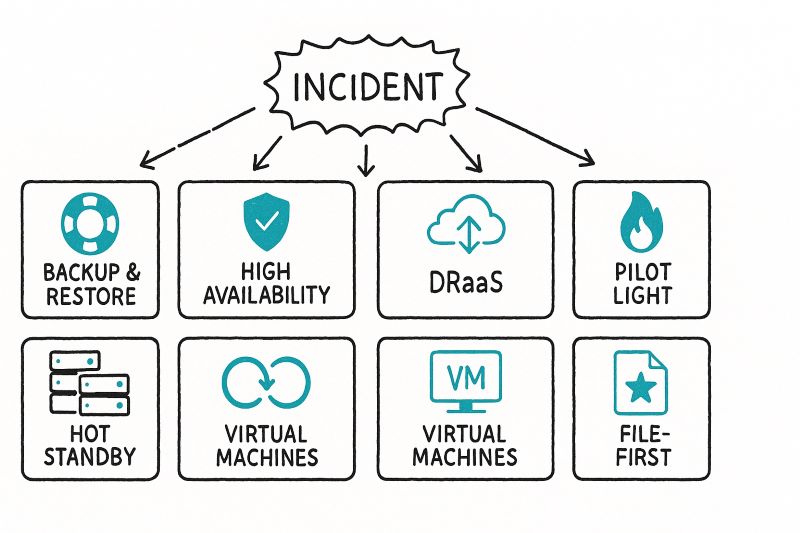
1. Automated Backup and Restore
Automated backup systems allow businesses to continuously copy critical data to secure locations, either on-site, in the cloud, or both. When a disaster strikes, these backups can be quickly restored, minimizing data loss. For instance, if a server fails during a cyberattack, an automated restore process can bring a backup online within minutes, keeping operations running smoothly.
⏱️ Speed & data loss: Minutes to hours; only a few minutes of data might be lost.
💡 Best for: Any business that wants a fast and reliable way to recover files.
2. High Availability and Redundancy
High availability (HA) ensures that critical systems remain accessible even during failures. Redundancy involves maintaining duplicate infrastructure or systems so that if one fails, another can take over. For example, a company might host its database across multiple servers in different geographic locations to prevent downtime caused by a single-site outage.This concept is the foundation of more advanced recovery setups like Hot Standby or Active–Active systems, which we'll look at next.
⏱️ Speed & data loss: Minutes to hours; almost no data lost.
💡 Best for: Services that cannot afford to be offline for long periods.
3. Disaster-Recovery-as-a-Service (DRaaS)
Instead of managing recovery systems yourself, DRaaS lets a provider handle everything for you, from data backup to failover and testing. Outsourcing disaster recovery through DRaaS has become increasingly popular. A third-party provider maintains the infrastructure, manages failover/failback processes, and ensures rapid resumption of critical operations. This approach reduces the burden on in-house IT teams and offers predictable, reliable recovery. According to recent industry data, the DRaaS market is projected to continue growing at a double-digit rate, reflecting rising corporate awareness of data security and continuity.
⏱️ Speed & data loss: Depends on the service plan.
💡 Best for: Small teams or companies that want expert help with minimal risk.
4. Pilot Light (Cloud)
Pilot Light keeps a small, basic system running in the cloud at all times. When a disaster occurs, you "turn on" the rest of the system quickly. For example, a small e-commerce site might only keep its core database active in the cloud. If the main server fails, additional servers can start in minutes, restoring full functionality. This method saves money compared to keeping a full system running all the time.
⏱️ Speed & data loss: Hours downtime; a few minutes to hours of data may be lost.
💡 Best for: Apps that can tolerate short downtime and want to save costs.
5. Hot Standby & Active–Active
Hot Standby keeps a complete copy of your system ready to take over immediately (It's "hot" because it's running and waiting). Active–Active runs multiple live systems at once, automatically switching traffic if one fails. For instance, an online bank might run two full data centers. If one fails, the other handles all user requests without interruption. This approach ensures customers rarely notice any downtime.
⏱️ Speed & data loss: Hot Standby: minutes; Active–Active: almost instant.
💡 Best for: Customer-facing apps that must always be online.
6. Virtual Machines / Images
This method involves keeping copies of virtual computers (VMs) or containers ready to start at another location. If a system fails, you can boot the virtual copy immediately. For example, a software company using containerized apps can quickly restore services by launching the container on a backup server. This makes recovery faster without needing to rebuild the system from scratch.
⏱️ Speed & data loss: Minutes to hours; very little data lost.
💡 Best for: Teams already using virtual machines or containers.
7. Database-First Recovery
In database-first recovery, the most important data (usually in databases) is restored before other systems. For example, an online shop might recover its order database first so that sales data is preserved, even if other systems take longer to restore. This ensures critical operations can continue while less important systems are still being fixed.
⏱️ Speed & data loss: Minutes to hours; seconds to minutes of data may be lost.
💡 Best for: Finance, orders, or any system where data is the highest priority.
8. Endpoint / File-First Recovery
Unlike full-system backups, this method focuses on saving individual files from personal devices like laptops or shared drives. This method automatically backs up files from laptops, desktops, and shared drives. If someone accidentally deletes a document or a laptop is damaged, files can be quickly restored. For example, a marketing team working on multiple shared documents can recover the latest versions within minutes, avoiding lost work.
⏱️ Speed & data loss: Minutes to hours; a few minutes to hours of data may be lost.
💡 Best for: Document-heavy workflows and small businesses.

Compare top endpoint management software in 2026, including Intune, Workspace ONE, ManageEngine, Ivanti, and AnySecura, for secure device management and DLP.Learn more>>
Modern Tools That Make DRP Easier
Good tools reduce manual work and uncertainty. Below is how AnySecura, an enterprise-grade information security platform, helps SMBs achieve reliable, low-friction recovery, especially for unstructured data (documents, spreadsheets, designs) scattered across endpoints.
How AnySecura's Cloud Document Backup Supports Your DRP
AnySecura focuses on fast, reliable file protection across all endpoints so you can hit practical RTO/RPO targets, prove recoverability, and pass audits with clear evidence. Key capabilities below are taken from the product page.

- Instant + Scheduled + Full-Disk Coverage: Captures every file change in real time, supports scheduled jobs, and runs full-disk scans so important documents aren't missed—even if a device was offline. This breadth gives you clean points to restore from during incidents.
- Flexible Backup Policies: Set rules by file type, size, include/exclude lists, intervals, and bandwidth limits, and keep multiple historical versions—so teams like Finance or Design can back up on their own rhythms without wasting storage.
- Backup Management & Search: Browse visual directories, find files quickly with multi-condition search, and control access by role—speeding up restores and keeping sensitive data restricted.
- Efficient Versions & Storage: Avoid duplicate uploads, get low-space alerts, and auto-clean old backups to keep costs down and jobs healthy—useful for large teams and long retention.
- Detailed Audit Logs: Track every backup and admin action to prove who did what, when—helping with compliance checks and post-incident reviews.
- Built for "No-Miss" Backups: A high-efficiency monitoring engine records document changes immediately, reducing the chance of gaps that slow recovery.
In short, real-time, policy-driven backups create frequent restore points for tighter RPOs, while fast search and rich version history make file recovery quicker, improving your RTO. Add built-in audit trails, and you have clear proof for customers and regulators—everything managed from a single, simple dashboard.
Because it runs continuously in the background, AnySecura's document backup raises your DRP confidence without forcing users to change how they work. You get consistent, restorable versions and clear evidence that recovery actually works.
👉 Want to learn about AnySecura's Cloud Document Backup?
See how AnySecura backs up documents across all devices in the cloud automatically, so teams recover fast from mistakes.
Read More5 Steps To Build A DRP: A Practical Checklist
1. Set Your Targets (RTO & RPO)
Agree with leadership on RTO and RPO per system and data class (e.g., ERP: RTO 4h/RPO 15m; shared documents: RTO 8h/RPO 1h). These numbers drive your technology choices and budget.
2. Inventory Critical Assets
- List applications, servers, endpoints, shared folders, and SaaS data exports.
- Map dependencies (DNS, identity, file shares, VPN, cloud buckets).
- Locate where documents actually live (laptops, network drives, cloud apps).
3. Choose Recovery Strategies
- Backups: Continuous or scheduled, versioned, encrypted, and off-site (3-2-1 rule where possible).
- Replication/Failover: For low RTO systems, use warm or hot standby.
- Prioritization: Recover identity, networks, and file services before apps that depend on them.
For documents, turn on AnySecura Cloud Document Backup to get automatic versioning and quick point-in-time restores. It helps you hit practical RTO/RPO for files without extra scripts or manual work.
4. Write Runbooks People Can Follow
- Plain, step-wise instructions (one action per line; include screenshots/paths if helpful).
- Include validation steps (e.g., "Verify share \\files01 is mounted and last modified time ≤ RPO").
- Embed contact lists and vendor SLAs.
5. Test, Measure, Improve
- Run a quarterly restore test of representative files and at least one key application.
- Track achieved RTO/RPO vs. targets; adjust tooling or scope accordingly.
- Document lessons learned and update the plan with version control.
FAQ about DRP Meaning
How can a DRP save company from major losses?
A DRP cuts downtime and data loss, which is where most costs pile up. With clear RTO/RPO targets, a tested restore checklist, and clean backups, you turn a multi-day outage into a short delay—protecting revenue, avoiding fines, and keeping customer trust. Tools like AnySecura’s cloud document backup add frequent restore points and audit trails, so you recover fast and prove it.
Can I create a DRP easily without technical expertise?
Yes. Start simple: pick one critical folder, set basic targets (e.g., RTO 4h, RPO 1h), turn on automated cloud backups with versioning (e.g., AnySecura), write a 10-line restore checklist, and run a 15-minute test. You can expand later, but this “minimum viable DRP” works now.
Conclusion
A Disaster Recovery Plan (DRP) isn't just a document, it's your safety net when the unexpected happens. Understanding DRP meaning helps businesses prepare for data loss, downtime, and cyber threats with confidence.
With the right plan and the right tool, recovery doesn't have to be complicated. AnySecura brings automation, transparency, and top-tier security into one unified platform, making disaster recovery faster, simpler, and more reliable than ever.
Ready to protect your business from data loss?, your all-in-one disaster recovery and backup solution.
