If your machine learning model performs perfectly in testing but fails in production, you’re likely facing data leakage—one of the most expensive, hidden risks in AI.
Data leakage can compromise your models, distort predictions, and lead to costly mistakes if left unchecked. In this article, we’ll explain what data leakage in machine learning is and share practical strategies to prevent it.

What Is Data Leakage in Machine Learning
Data leakage in machine learning happens when details outside the training set slip into the training process. This causes the model to learn from information that would not exist at prediction time.
Put plainly, data leakage in machine learning is like giving the model access to the exam answers during training. The model seems to perform well during testing, but once deployed, its performance drops because it never truly learned how to solve the problem.
Consider a model forecasting whether a customer will end a subscription. If the training table holds a column like “account closure date,” the model achieves perfect accuracy on the test split. In live use, that column stays empty until the cancellation occurs, so the same model fails. This is a typical example of target leakage in machine learning.
The type of data leakage in machine learning often depends on what information is included in the training dataset.
- Target Leakage occurs when training data includes information that directly reveals the outcome the model is trying to predict.
- Train-Test Contamination occurs when the training data includes information from the test dataset.
- Feature Leakage occurs when the training data includes information that would not be available during real predictions.
Models affected by data leakage in machine learning can create serious risks. Organizations may mistakenly trust and deploy flawed models, investing resources while making decisions based on unreliable predictions, leading to business losses. In severe cases, datasets may contain sensitive customer data or financial records, causing legal liabilities and regulatory penalties.
5 Methods to Prevent Data Leakage in Machine Learning
Preventing data leakage in machine learning requires a combination of engineering practices, data governance, and enterprise security controls. Organizations must not only design proper ML pipelines but also ensure that sensitive datasets are protected throughout the entire data lifecycle. The following best practices can help reduce the risk.
Method 1. Separate Training and Testing Datasets
The most frequent cause of data leakage in machine learning is train-test contamination. This happens when part of the test set slips into the training set.
To prevent it, your team must keep every data split in the machine learning workflow apart from the others:
- training datasets used to train the model
- validation datasets used for tuning model parameters
- testing datasets used to evaluate model performance

To reduce the risk of human error, teams can use automated scripts or validation tools to verify dataset splits and ensure that data from the test set does not appear in the training process.
Method 2. Audit Data Sources and Data Flow
Machine learning datasets often come from multiple sources: databases, external APIs, cloud storage, or internal business systems. If no audit trail exists, no one can tell where data originates and how it moves through the pipeline.
Organizations should maintain visibility into:
- data sources used for model training
- how datasets are processed and transformed
- where training data is stored and shared
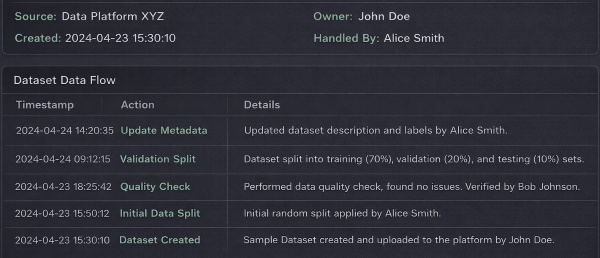
To support this, teams should record dataset metadata (such as source, owner, and creation time), log data processing activities, and track dataset access and transfers. When this information is stored in one clear chain, the organization sees the exact path that each piece of data has travelled. That visible path lets the organization spot weak points plus stop data from leaving the system through an attack or a mistake.
Method 3. Strict Access Control
Training datasets often contain sensitive details, such as customer records, financial figures or proprietary business information. If access controls are absent, people without permission view, copy or misuse those datasets.
Each organization needs a clear access control policy so that only approved staff members reach the training data.
- define role-based access permissions for datasets
- restrict access to sensitive data based on job responsibilities
- review and update access permissions regularly
For highly sensitive datasets, additional approval workflows can be introduced so that access requests must be reviewed by designated supervisors. These controls help reduce the risk of internal data leakage and unauthorized dataset usage.
Method 4. Data Masking or Encryption
Sensitive information within training datasets should be protected through data masking or encryption techniques. This helps prevent confidential data from being exposed during model training or data processing.
Organizations can apply several protection methods:
- mask sensitive fields such as names, ID numbers, or contact details
- replace personal identifiers with hashed values or anonymous IDs
- encrypt datasets during storage and transmission
Using secure protocols such as TLS protects data during network transfer, while encrypting stored datasets ensures that unauthorized users cannot read the data even if they gain access to the files.
Method 5. Monitor Anomalous Activities
Even with strong access control and encryption measures in place, organizations should continuously monitor how training datasets are used. Real-time monitoring helps detect unusual behavior that may indicate potential data leakage.
Examples of anomalous activities include:
- unusually large dataset downloads
- uploading training data to external cloud services
- copying datasets to unauthorized devices
To monitor these activities, organizations can deploy behavior monitoring tools that track file access, data transfers, and user activities across endpoints. These tools allow security teams to quickly identify and investigate potential data leakage incidents before sensitive information is exposed.
AnySecura: Enterprise-Grade Protection for ML Data Security
Preventing data leakage in machine learning isn’t just about ML engineering—it’s about building a secure data ecosystem. Organizations need tools that enforce access control, protect sensitive datasets, track data usage, and detect anomalies—all without disrupting workflow. That’s where AnySecura comes in.
AnySecura provides multiple layers of protection that help enterprises secure AI training data, monitor file activities, and prevent unauthorized data transfers.
What You Can Get with AnySecura?
- Granular Data Access Control: AnySecura gives your team the ability to set detailed access rules for sensitive files and datasets. An administrator names the individual users, departments or roles that receive permission to reach training data, ensuring that only authorized staff members can view or modify sensitive datasets.
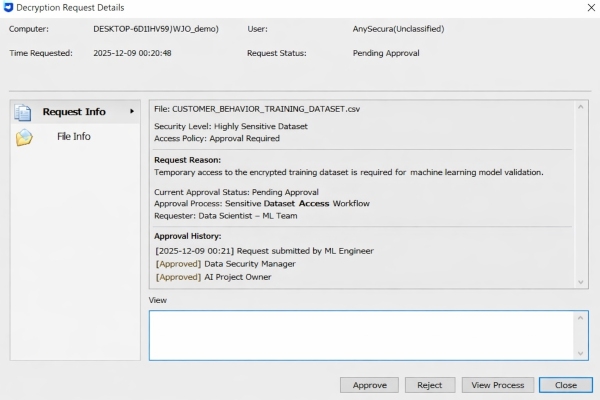
- Approval-Based Access Control: Highly sensitive datasets receive an additional safeguard - every attempt to open the files starts with a formal request. The person who wants the data sends a petition to one or more appointed approvers. Only after those officials grant explicit permission does the system unlock the information. This rule limits exposure to the moments when the data is truly needed and keeps the entire transaction under documented oversight.
- Transparent Encryption: Automatically protects sensitive files without disrupting normal workflows. The system encrypts each file as it is written to disk. A dataset that is copied, moved or placed outside the approved location stays unreadable unless the user holds the correct key. The design blocks unwanted data disclosure and keeps daily tasks running at full speed.
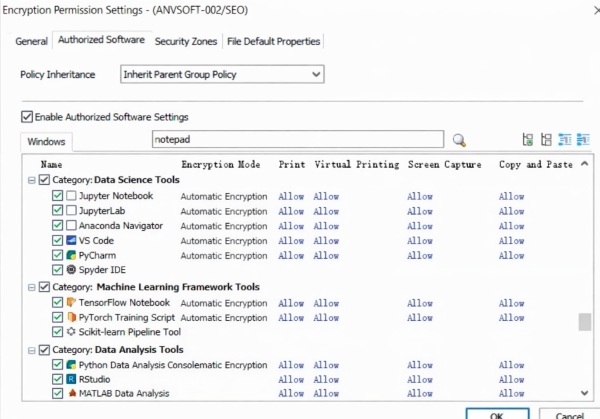
- Training Dataset Lifecycle Tracking: AnySecura provides full visibility into the lifecycle of sensitive datasets. Security teams can track how training data is created, accessed, modified, copied, and shared across systems. Detailed audit logs help organizations identify potential data leakage risks and maintain accountability for data usage.
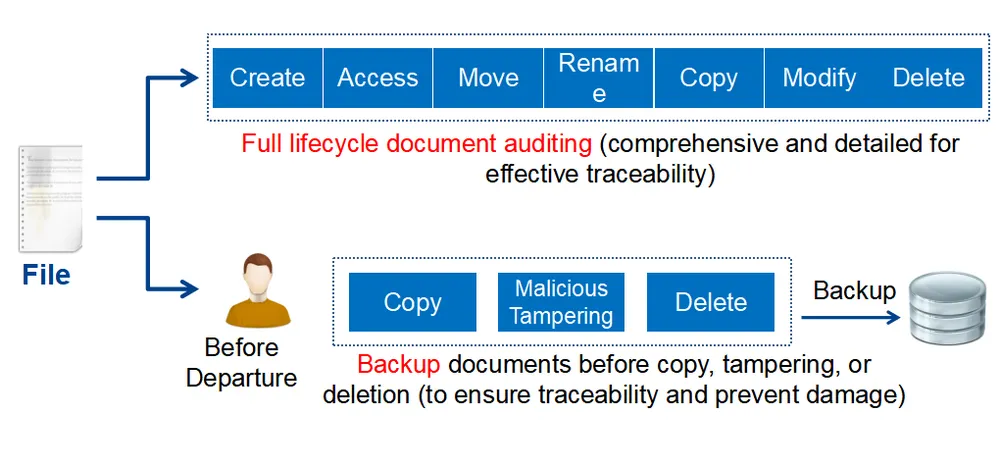
- Real-Time Monitoring of Abnormal Data Transfers: Continuously monitors user activities to detect abnormal data transfers or suspicious behavior, including unusually large dataset downloads / unauthorized copying of training files / abnormal uploads or file transfers. When suspicious activities are detected, administrators receive immediate alerts.
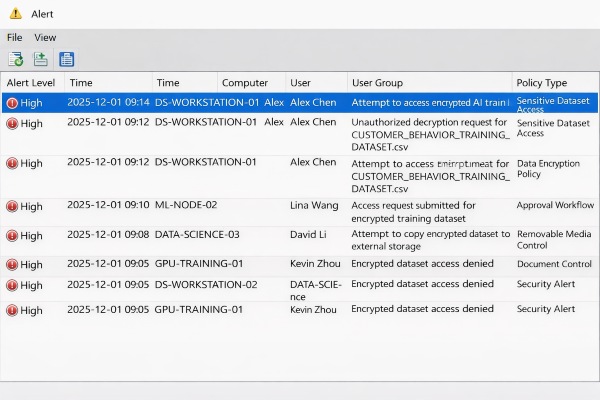

Discover top 5 employee monitoring software in 2026. Compare pros and cons to find the perfect tool for workforce management.Learn more>>
FAQs about AI Data Leakage
What industries face the highest risk of AI data leakage?
Organizations that rely heavily on sensitive data for machine learning are particularly exposed to data leakage risks.
Industries with high exposure include:
- financial services
- healthcare and medical research
- e-commerce and retail analytics
- technology companies developing AI models
- telecommunications providers
These industries handle large volumes of personal and proprietary data, making AI dataset security especially critical.
Why are AI training datasets attractive targets for attackers?
AI training datasets are attractive targets for attackers because they often contain large volumes of valuable, structured, and sensitive data collected from across an organization. Unlike many operational datasets, training data is typically aggregated from multiple systems, making it especially rich in information. This makes them highly vulnerable to data leakage in AI systems.
Conclusion
Data leakage in machine learning is often overlooked but critical. It usually stems from wider weaknesses in how data is governed, how data sets are handled and how security is supervised.
Try AnySecura if you would like to enforce access control, protect sensitive datasets through encryption, track the lifecycle of training data, and detect abnormal data activities in real time. With the right safeguards in place, enterprises can confidently develop and deploy machine learning models without putting their critical data assets at risk.
