How to Use the Sensitive Information Classification Library in Category Management - AnySecura Manual
This guide will help you master the Sensitive Information Classification Library, a core feature of AnySecura's Category Management module. You'll learn how to build the text-based rules that allow the system to automatically identify and classify your organization's documents.
We'll then explore how to organize these rules into Information Categories, which are the building blocks for applying security policies. You'll understand how to create, manage, and fine-tune these categories to effectively control document access and usage.
To help administrators manage internal documents, they first need to define text-based rules in the Sensitive Information Classification Library. The system uses these rules to automatically match internal documents and classify them. Combined with permissions set by the administrator for different document categories, the system can control and log the sharing and usage of documents based on their classification.
When setting text-based rules, administrators need to configure two types of categories: Feature Rules and Information Categories. Feature Rules define specific document-matching criteria, while Information Categories group different Feature Rules together to identify and classify documents.
Select "Category Management -> Sensitive Content Library" to open the library window.
| Operation | Description |
|---|---|
| New | Select the root node of Information Categories / Feature Rules, then choose "Action -> New" or click the New button on the toolbar to create a new Information Category or Feature Rule. |
| Search | Select "Action -> Search" or click the Search button |
| Show Hidden Feature Rules | Feature Rules imported from the Keyword Extraction Tool are hidden by default. Select "Action -> Show Hidden Feature Rules" to view them. |
| Import | Select "Action -> Import" and choose a classification library file to import previously exported Information Categories or Feature Rules. |
| Export | Select "Action -> Export" to export specific Information Categories or Feature Rules. Export options include:
|
Information Category Settings
| Operation | Description |
|---|---|
| Information Category Name | Administrators can define a custom name for the information category. Names must be unique. |
| Category Level |
|
| Notes | Optional notes or description for the information category. |
| Rule Group | Feature Rules included in the information category; multiple rules can be selected. |
| Rule Weight | Default weight is 100. Administrators can adjust it to any integer between 0–100. A document matches the information category only when the sum of matched Feature Rule weights reaches or exceeds 100. |
Feature Rule Settings
| Operation | Description |
|---|---|
| Feature Rule Name | Administrators can define a custom name for the feature rule. Names cannot start with "@" and must be unique. |
| Type | Specifies the type of content the feature rule will identify, including File Name, File Type, File Size, File Content, and File Properties:
|
| Content Scope |
|
| Deduplication |
|
| Case Sensitivity | When enabled, matching English text in the Include Content field is case-sensitive. |
| Hit Count | Specifies the minimum total number of occurrences of the text in Include Content required for a document to match this feature rule. Valid values are integers from 1 to 10,000. A document matches the rule only if the total occurrences meet or exceed this value. |
| Content Classification | Specifies the type of information in Include Content and Exclude Content. Options include Keyword and Regular Expression:
|
| Include Content | Defines the content used to match documents. Multiple entries are supported, separated by commas or line breaks.
|
| File Name | Content set here is used to match the target document's file name and storage path.
|
| File Type | Content set here is used to match the target document's file type.
|
| File Content | Content set here is used to match the target document's text. Support for Keyword and Regular Expression is the same as for File Name. |
| Exclude Content | Specifies content that should be ignored during matching. The rules follow the same format as Include Content, and Exclude Content takes priority over Include Content. |
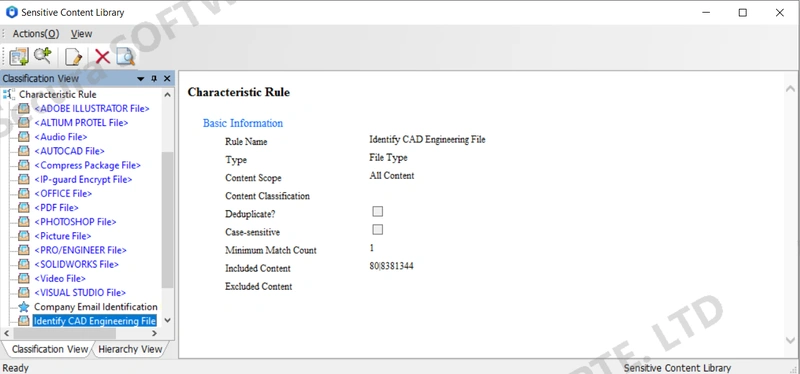
The feature rule library already includes predefined rules for commonly used file types based on File Type. These predefined rules are displayed in blue and cannot be deleted or modified.
The predefined library includes the following file types:
Adobe Illustrator files, Altium Protel files, AutoCAD files, AnySecura encrypted files, Office files, PDF files, Photoshop files, Pro/ENGINEER files, SOLIDWORKS files, Visual Studio files, video files, image files, compressed files, and audio files.
Some types have hidden subtypes by default. To view them, select "Action -> Show Hidden Feature Rules."
When setting up an information category, users can either use existing predefined feature rules or right-click a feature rule and select "New Feature Identification" to create custom feature rules.